BERT
Based on the lecture “Text Analytics (2024-1)” by Prof. Je Hyuk Lee, Dept. of Data Science, The Grad. School, Kookmin Univ.

BERT
-
버트(
BidirectionalEncoderRepresentations fromTransformers; BERT) : 트랜스포머의 인코더 아키텍처를 기반으로 하여 위키피디아(25억 단어), BooksCorpus(8억 단어) 등 레이블 없는 텍스트 데이터로 사전 훈련된 대형 언어 모형(Pre-trainedLargeLanguageModel)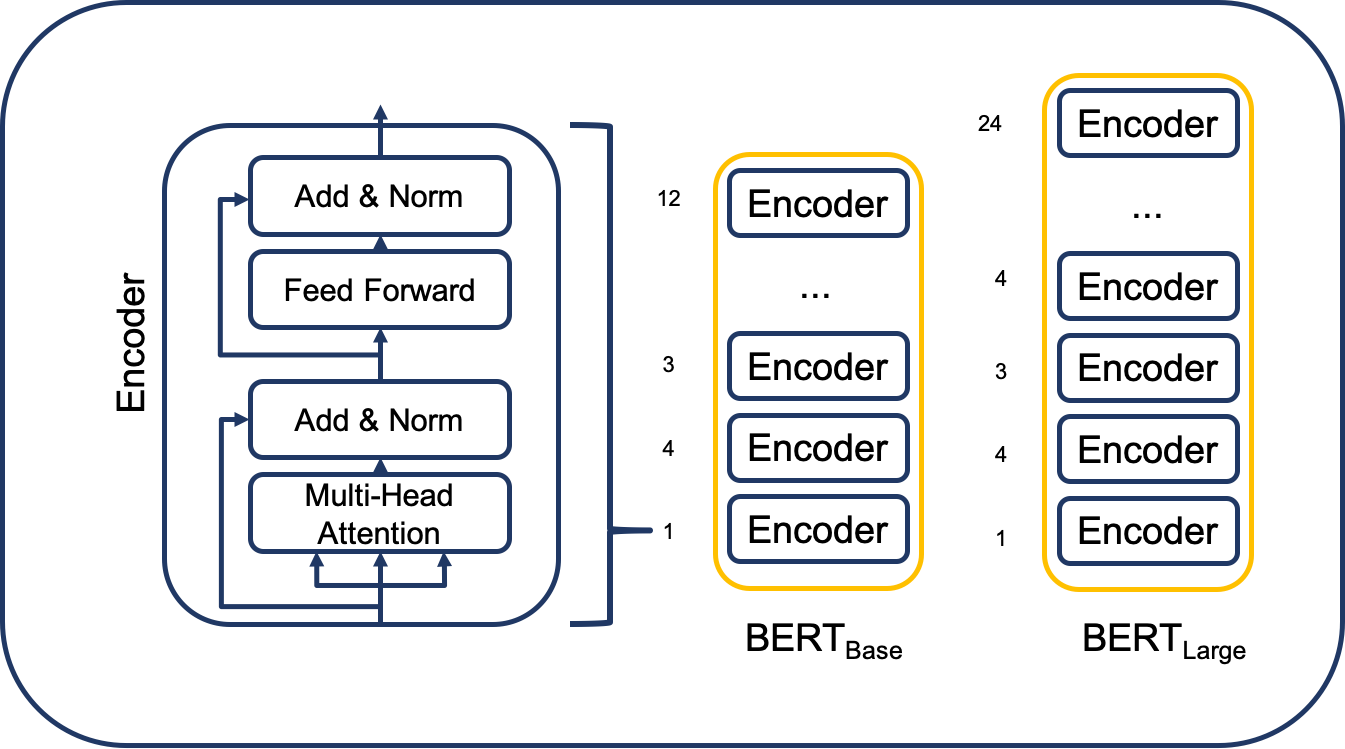
-
Version Comparison
BASE LARGE Embedding Dimension 768 1024 Encoder Layers 12 24 Attention Heads 12 16 Total Parameter 110M 340M
Word Representation
-
Unique(or Max) Number of Vector
VECTOR NUM Unique Tokens 30,522 Max Seq 512 Max Sentence 2 -
Each observation can contain up to two sequences
CLSmydogiscuteSEPhelikesplay##ingSEPCLS: 입력 정보를 종합하여 대표하는 벡터SEP: 문장 구분자
- Tokenization Method : Word-Piece Encoding
- 단어 사전에 존재하는 단어들로 쪼개고, 이때 내부 단어(Sub-Word)는 앞에
##을 표기하여 온전한 단어가 아님을 나타냄 - Here is the sentence I want embeddings for.
- [
here,is,the,sentence,i,want,em,##bed,##ding,##s,for,.]
- 단어 사전에 존재하는 단어들로 쪼개고, 이때 내부 단어(Sub-Word)는 앞에
-
Embedding
\[\begin{aligned} \mathbf{x}_{i} &= \mathbf{x}^{(i)}_{\text{TOKEN}} + \mathbf{x}^{(i)}_{\text{POS}} + \mathbf{x}^{(i)}_{\text{SEG}} \end{aligned}\]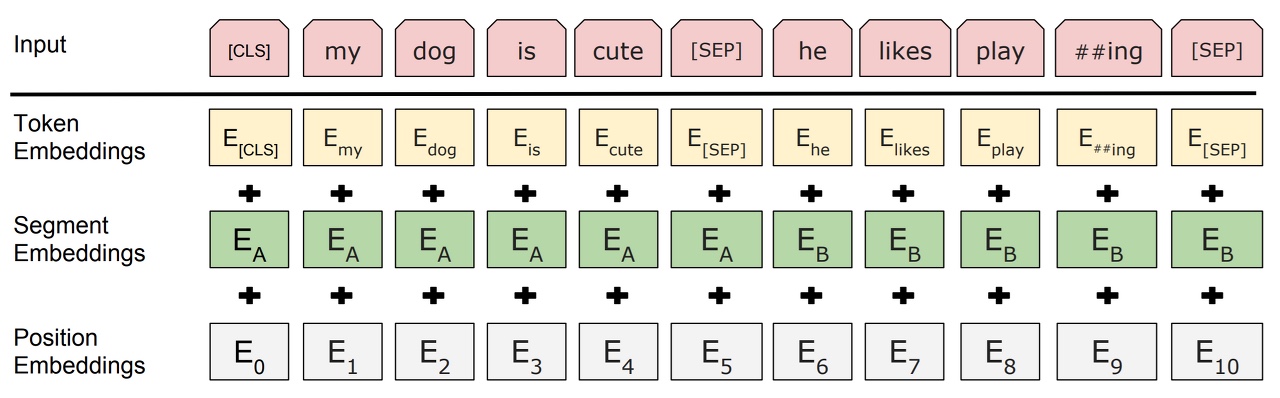
-
\(\mathbf{x}^{(i)}_{\text{TOKEN}}\) : Token Embedding
-
\(\\mathbf{x}^{(i)}_{\text{POS}}\) : Position Embedding, Not Fixed But Learnable
-
\(\mathbf{x}^{(i)}_{\text{SEG}}\) : Segment Embedding
Token Segment Embedding CLSFirst Sequence Vector Tokens @ First Sequence First Sequence Vector SEPFirst Sequence Vector Tokens @ Second Sequence Second Sequence Vector SEPSecond Sequence Vector
-
Single Layer
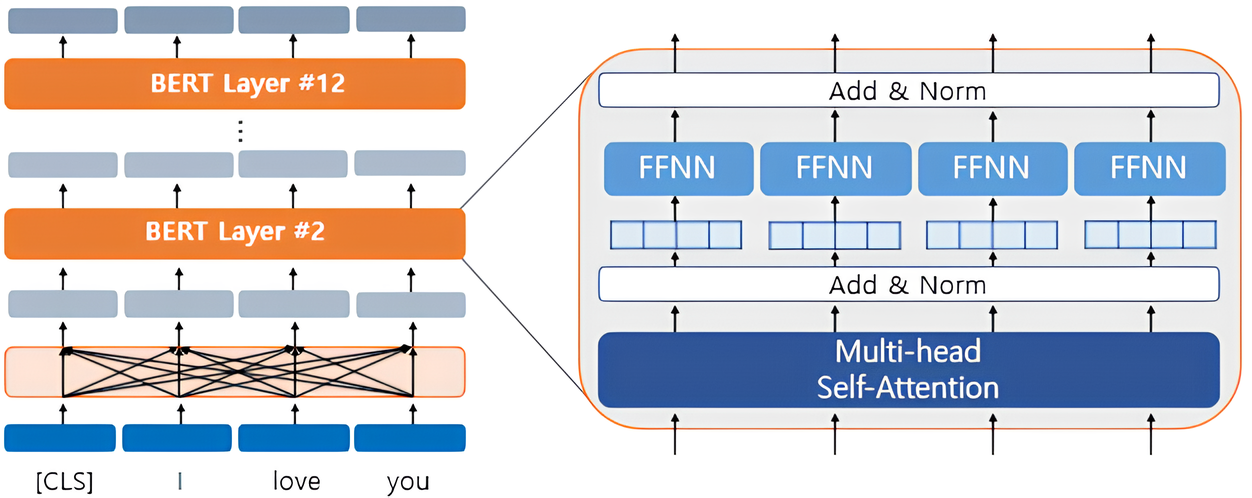
- $\mathbf{X}$ is Input Data of Single Layer, $\mathbf{Y}$ is Output Data of Single Layer
- \(\mathbf{X}^{(k+1)}=\mathbf{Y}^{(k)}\) : Input Data of $k+1$ Encoder Layer is Output Data of $k$
- Input Data of Initial Layer \(\mathbf{X}^{(0)}\) is Sum of Token Embedding & Position Embedding & Segment Embedding Vector
- Output Data of Final Layer \(\mathbf{Z}=\mathbf{Y}^{(K)}\) is Output of BERT Module
-
\(\text{Multi-Head}\left(\mathbf{X}^{(k)}\right)\) : Multi-Head Self Attention
-
\(\text{FFN}\left(\mathbf{H}^{(k)}\right)\) :
\[\begin{aligned} \text{FFN}\left(\mathbf{H}^{(k)}\right) &=\mathbf{W}^{(k)}_{2} \cdot \left(\text{ReLU}\left[\mathbf{W}^{(k)}_{1} \cdot \mathbf{H}^{(k)} + \mathbf{b}^{(k)}_{1}\right]\right) + \\mathbf{b}^{(k)}_{2} \end{aligned}\]Feed-ForwardNetworks- $\mathbf{W}^{(k)}_{1} \in \mathbb{R}^{M \times 4d}$ : Dimension Expansion to four times the Dimension of the Embedding Vector
- $\mathbf{W}^{(k)}_{2} \in \mathbb{R}^{M \times d}$ : Dimension Reduction to Embedding Vector Dimension
Pre-Training for Transfer Learning
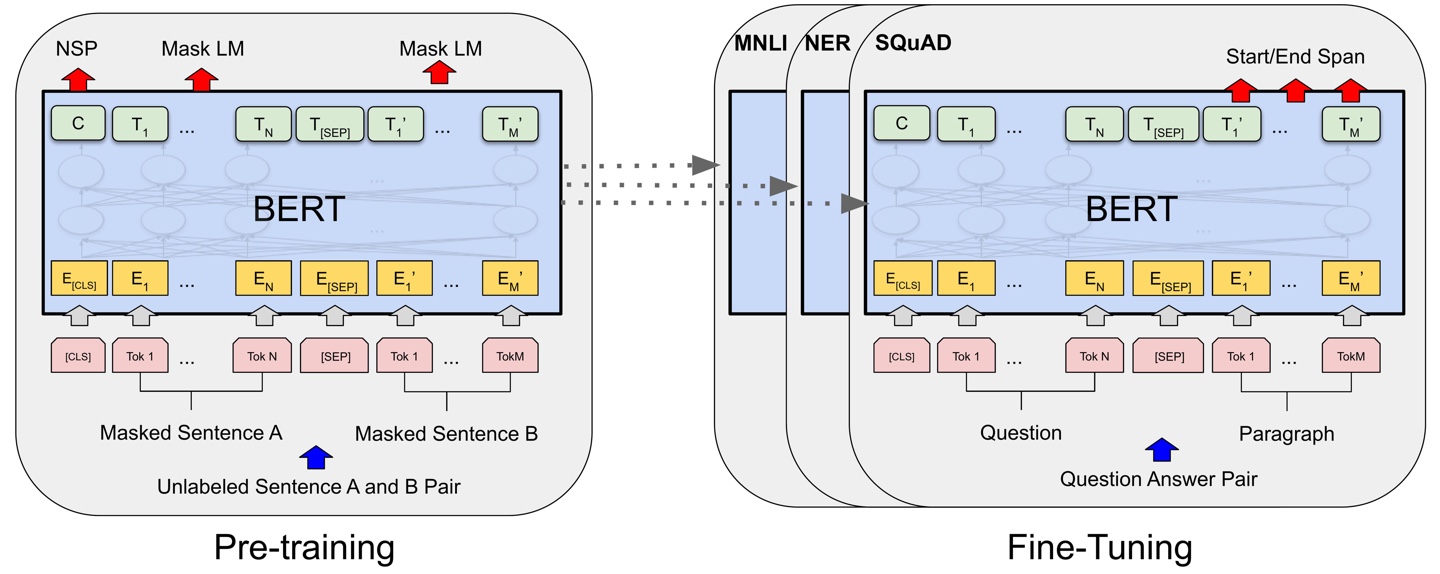
-
MLM(
MaskedLanguageModel) : 입력 문장에서 일부는MASK로 가리고, 일부는 다른 단어로 무작위 변경한 후(10%), 원래 단어를 예측하도록 양방향 학습함으로써 일반화된 언어 패턴을 학습하고 문맥을 이해하는 능력을 강화함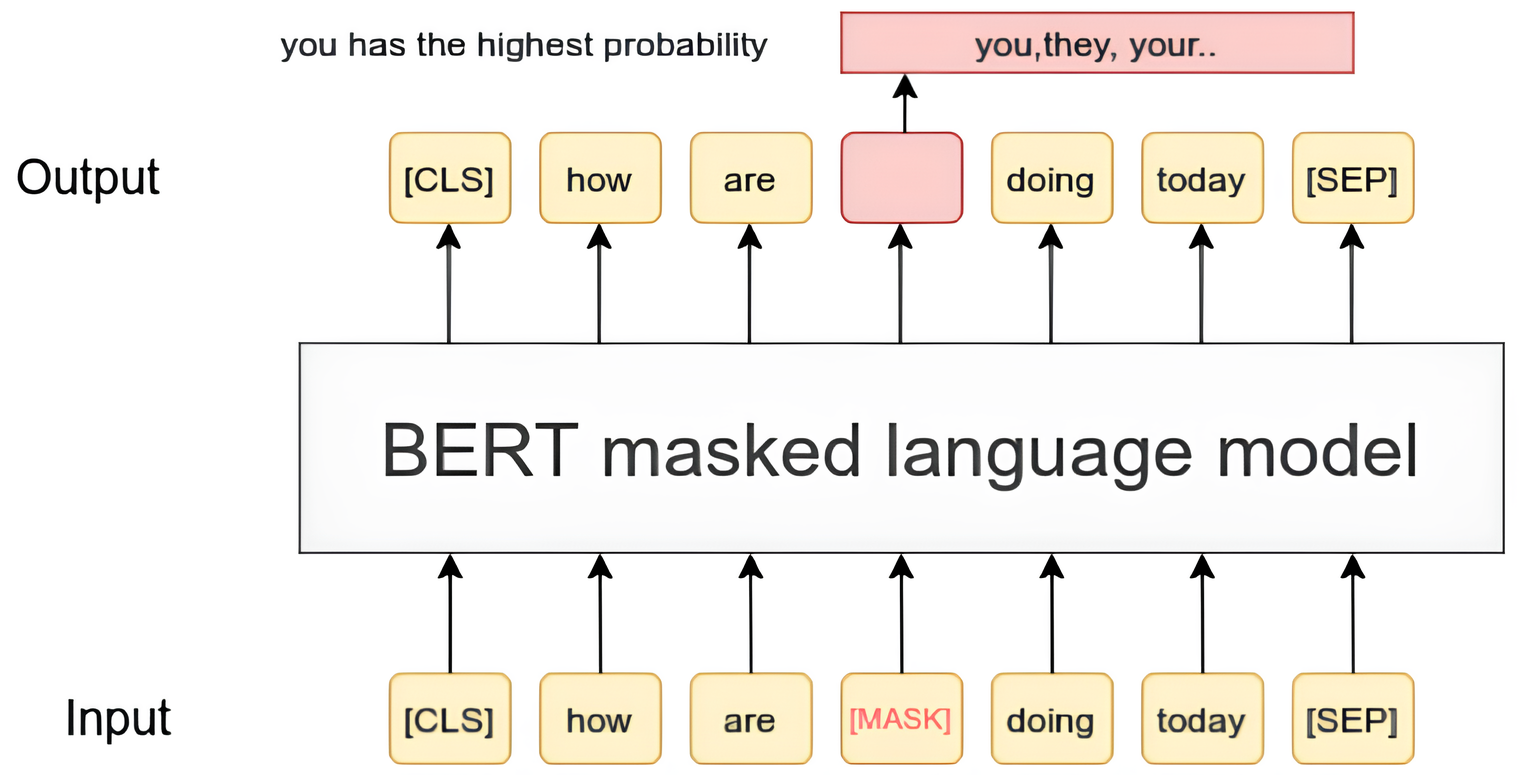
-
Bidirection : 트랜스포머 디코더가 단방향 예측($t-1$ 시점까지 정보를 기반으로 $t$ 시점을 예측)을 수행했던 것과 달리, 버트는 양방향 예측(이전 시점과 이후 시점의 정보를 종합하여 $t$ 시점을 예측)을 수행하므로, 문맥 벡터 생성 시 미래 순번 정보를 모두 마스킹 처리하지 않음
-
How to Process Target
역할 처리 방법 비중 CONTEXT 변경하지 않음 85% PREDICTION MASK 12% PREDICTION 무작위 변경 1.5% PREDICTION 변경하지 않음 1.5%
-
-
NSP(
NextSentencePrediction) :CLS토큰을 기반으로 두 문장이 연속된 문장인지 아닌지 예측하도록 학습함으로써 문장 간 관계를 학습함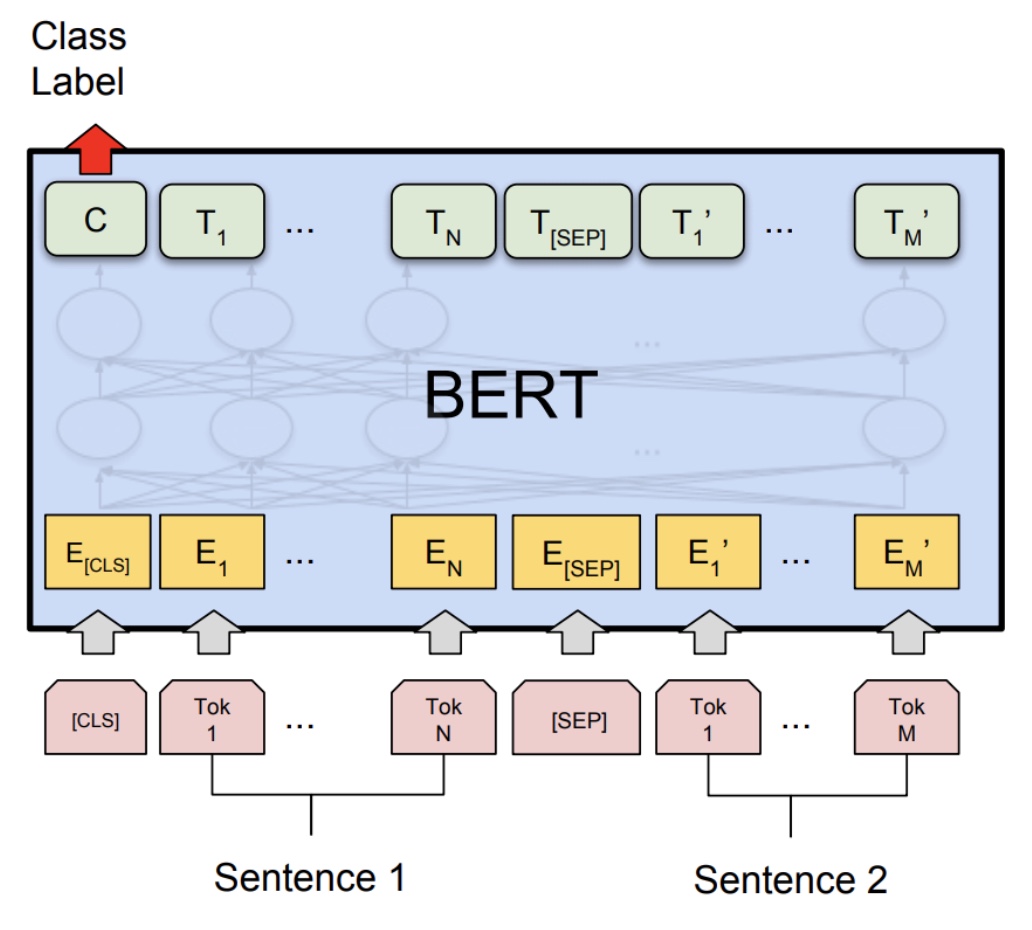
Sourse
- https://pub.towardsai.net/demystifying-bert-efe9ac3c1c74
- https://www.sbert.net/examples/unsupervised_learning/MLM/README.html
- https://wikidocs.net/115055