BPR
- Title:
BPR: Bayesian Personalized Ranking from Implicit Feedback - Published: 2009
- Data Set:

BPR
-
BPR(
BayesianPersonalizedRanking) : Probabilistc Pairwise Ranking Prediction선행 연구들은 대체로 평점 예측에 집중하는 경향을 보였으며, 이는 명시적 피드백 환경에 적합함. 하지만 실제에서는 주로 암묵적 피드백이 사용되며, 때문에 개별 아이템의 평점을 정확히 맞추는 것보다는 중요한 상호작용 정보과 중요하지 않은 상호작용 정보 간 차등을 두는 (아이템 간 선호 순위를 맞추는) 목적 함수가 요구됨.
AUC Optimization
-
ROC(
\[\begin{aligned} \text{ROC} &=\left\{(x,y) \mid t \in [0,1]\right\} \end{aligned}\]ReceiverOperatingCharacteristic) is the set of $(x, y)$ pairs for all threshold $t$ values:-
$x$ is FPR(
\[\begin{aligned} x &=f(t)\\ &=p\left(\hat{z} > t\mid z=\text{NEG}\right) \end{aligned}\]FalsePositiveRate): -
$y$ is TPR(
\[\begin{aligned} y &=g(t)\\ &=p\left(\hat{z} > t\mid z=\text{POS}\right) \end{aligned}\]TruePositiveRate):
-
-
AUC(
\[\begin{aligned} \text{AUC} &=\int_{0}^{1}{g \circ f^{-1}\left(x\right)\text{d}x} \end{aligned}\]AreaUnder theCurve) is the area under the ROC curve: -
Convert to Probability
-
$f(t), g(t)$ is related to CDF(
\[\begin{aligned} f(t) &= p\left(\hat{z} > t\mid z=\text{NEG}\right)\\ &= 1 - \underbrace{p\left(\hat{z} \le t\mid z=\text{NEG}\right)}_{\text{CDF}}\\ \\ g(t) &= p\left(\hat{z} > t\mid z=\text{POS}\right)\\ &= 1 - \underbrace{p\left(\hat{z} \le t\mid z=\text{POS}\right)}_{\text{CDF}} \end{aligned}\]CumulativeDistributionFunction): -
Change of Variables:
\[\begin{aligned} \frac{\text{d}x}{\text{d}t} &= \frac{\text{d}f(t)}{\text{d}t}\\ &= -\underbrace{p\left(\hat{z}=t \mid z=\text{NEG}\right)}_{\text{PDF}}\\ \\ \therefore \text{d}x &= -p\left(\hat{z}=t \mid z=\text{NEG}\right)\text{d}t \end{aligned}\] -
Therefore:
\[\begin{aligned} \text{AUC} &=\int_{x=0}^{x=1}{g \circ f^{-1}\left(x\right)\text{d}x}\\ &= \int_{t=1}^{t=0}{g(t) \frac{\text{d}f(t)}{\text{d}t} \text{d}t}\\ &= -\int_{t=0}^{t=1}{g(t) \frac{\text{d}f(t)}{\text{d}t} \text{d}t}\\ &= \int_{t=0}^{t=1}{p\left(\hat{z} > t\mid z=\text{POS}\right) p\left(\hat{z}=t \mid z=\text{NEG}\right)\text{d}t}\\ &= \int_{t=0}^{t=1}\int_{\tau>t}{p\left(\hat{z} = \tau\mid z=\text{POS}\right) p\left(\hat{z}=t \mid z=\text{NEG}\right)\text{d}t}\\ &= p(\hat{z}_{\text{POS}} > \hat{z}_{\text{NEG}}) \end{aligned}\]
-
Data Set
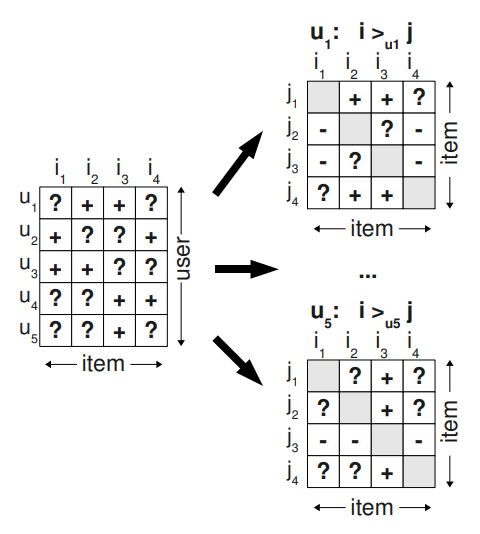
- 학습 데이터 : 개별 사용자 $u$ 의 선호체계 $>_{u}$
-
비교 가능성(Totality)
\[\forall i,j \in I:\quad i \ne j \quad \Rightarrow \quad \left(i >_{u} j\right) \vee \left(j >_{u} i\right)\] -
반대칭성(Anti-Symmetry)
\[\forall i,j \in I:\quad \left(i >_{u} j\right) \wedge \left(j >_{u} i\right) \quad \Rightarrow \quad i = j\] -
이행성(Transitivity)
\[\forall i,j,k \in I:\quad \left(i >_{u} j\right) \wedge \left(j >_{u} k\right) \quad \Rightarrow \quad \left(i >_{u} k\right)\]
-
-
Pair-wise Preference Data Set
\[\Omega = \Big\{(u,i,j) \mid i \in I_{u} \wedge j \in I \setminus I_{u}\Big\}\]- $I$ : 아이템 집합
- $I_{u} \subset I$ : 사용자 $u$ 가 상호작용한 아이템 집합
- $i \in I_{u}$ : 사용자 $u$ 가 상호작용한 아이템
- $j \in I \setminus I_{u}$ : 사용자 $u$ 가 상호작용하지 아니한 아이템
-
Single Data Point Definition
\[x_{u,i,j}:=r_{u,i} - r_{u,j}\]
How to Modeling
Posterior Estimation
\[\underbrace{\ln{P(\Theta \mid \mathcal{D})}}_{\begin{array}{c} \text{Objective Function} \\ \text{(Log Posterior)} \end{array}} \propto \underbrace{\ln{P(\mathcal{D} \mid \Theta)}}_{\text{Log Likelihood}} + \underbrace{\ln{P(\Theta)}}_{\text{Log Prior}}\]-
Log Likelihood
-
Likelihood of Single Data Point
\[\begin{aligned} P(i >_{u} j \mid \Theta) &= \sigma\left(\hat{x}_{u,i,j}\right) \end{aligned}\] -
Likelihood of Data Set
\[\begin{aligned} P(\mathcal{D} \mid \Theta) &= \prod_{(u,i,j)\in\Omega}{P(i >_{u} j \mid \Theta)}\\ &= \prod_{(u,i,j)\in\Omega}{\sigma\left(\hat{x}_{u,i,j}\right)} \end{aligned}\] -
Log Likelihood
\[\begin{aligned} \ln{P(\mathcal{D} \mid \Theta)} &= \ln{\prod_{(u,i,j)\in\Omega}{P(i >_{u} j \mid \Theta)}}\\ &= \sum_{(u,i,j)\in\Omega}{\ln{P(i >_{u} j \mid \Theta)}}\\ &= \sum_{(u,i,j)\in\Omega}{\ln{\sigma\left(\hat{x}_{u,i,j}\right)}} \end{aligned}\]
-
-
Prior Determination; $\Theta \sim \mathcal{N}\left(0, \lambda_{\Theta}^{-1}\mathbf{I}\right)$
\[\begin{aligned} P\left(\Theta\right) &= \frac{1}{(2\pi)^{d/2} \cdot \lambda_{\Theta}^{d/2}} \cdot \exp \left[-\frac{\lambda_{\Theta}}{2}\Vert \Theta \Vert^{2}\right]\\ \\ \ln{P\left(\Theta\right)} &= \ln{\frac{1}{(2\pi)^{d/2} \cdot \lambda_{\Theta}^{d/2}} \cdot \exp \left[-\frac{\lambda_{\Theta}}{2}\Vert \Theta \Vert^{2}\right]}\\ &= \ln{\frac{1}{(2\pi)^{d/2} \cdot \lambda_{\Theta}^{d/2}}} - \frac{\lambda_{\Theta}}{2}\Vert \Theta \Vert^{2}\\ &\propto -\lambda_{\Theta}\Vert\Theta\Vert^{2} \end{aligned}\] -
Posterior Estimation
\[\begin{aligned} P(\Theta \mid \mathcal{D}) &\propto P(\mathcal{D} \mid \Theta) \cdot P(\Theta)\\ \\ \ln{P(\Theta \mid \mathcal{D})} &\propto \ln{P(\mathcal{D} \mid \Theta)} + \ln{P(\Theta)}\\ &\propto \sum_{(u,i,j)\in\Omega}{\ln{\sigma\left(\hat{x}_{u,i,j}\right)}} -\lambda_{\Theta}\Vert\Theta\Vert^{2} \end{aligned}\]
Optimization
-
Objective Function
\[\text{BPR-OPT} = \ln{P(\Theta \mid \mathcal{D})}\] -
Optimization
\[\begin{aligned} \hat{\Theta} &= \text{arg} \max_{\Theta}{\ln{P(\Theta \mid \mathcal{D})}}\\ &= \text{arg} \max_{\Theta}{\sum_{(u,i,j)\in\Omega}{\ln{\sigma\left(\hat{x}_{u,i,j}\right)}} - \lambda_{\Theta}\Vert\Theta\Vert^{2}}\\ &= \text{arg} \min_{\Theta}{\sum_{(u,i,j)\in\Omega}{-\ln{\sigma\left(\hat{x}_{u,i,j}\right)}} + \lambda_{\Theta}\Vert\Theta\Vert^{2}} \end{aligned}\]- $\hat{\Theta}$ is MAP(Maximum a Posteriori) Estimator