What? Data Science
Based on the lecture “Intro. to Machine Learning (2023-2)” by Prof. Je Hyuk Lee, Dept. of Data Science, The Grad. School, Kookmin Univ.

Data-Driven Decision Making
Data-Driven Decision Making Process
- Descriptive : Explains What Happend
- Comprehensive, Accurate, Live Data
- Effective Visualisation
- Diagnostic : Explains Why It Happend
- Ability to Drill Down to the Root-cause
- Ability to Isolate All Confounding Information
- Predictive : Forcasts What Might Happned
- Business Have Remained Fairly Consistent Over Time
- Historical Patterns Being Used to Predict Specific Outcomes Using Algorithms
- Decisions are Automated Using Algorithms and Tech.
- Prescriptive : What Do I Need to Do?
- Recommends Action Based On The Forecast
- Applying Advanced Analytical Techs to Make Specific Recommendatons
Data-Driven Problem-Solving Process
-
문제 정의
어떤 문제를 해결할 것인가? 이를 위해 필요한 데이터는 무엇인가?
-
데이터 획득
어떻게 데이터를 수집할 것인가?
-
데이터 탐색
데이터 전처리 탐색적 자료 분석
-
모델링
문제에 맞는 기계학습 알고리즘 선택 모델 구축
-
배포
제품 배포 및 시스템 유지 보수
Data Science
-
데이터 과학(Data Science)
정형, 비정형의 다양한 데이터로부터 지식 및 시사점을 도출하는 데 과학적 방법론을 동원하는 융합 분야(출처 : 위키백과)
-
빅데이터(Bigdata)
통상적으로 사용되는 데이터 수집, 관리, 처리 소프트웨어의 수용 한계를 넘어서는 크기의 데이터(출처 : 위키백과)
- Volume(Data Quantity)
- Variety(Data Types)
- Velocity(Data Speed)
- Value(Data Impact)
-
데이터 마이닝(Data Mining)
대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 짜임을 분석하여 가치 있는 정보를 빼내는 과정(출처 : 위키백과)
-
기계학습(Machine Learning)
기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야(출처 : 위키백과)
-
인공지능(Artificial Intelligence; AI)
인간의 학습, 추론, 지각 능력을 인공적으로 구현하려는 컴퓨터 과학의 세부 분야(출처 : 위키백과)
Type of Machine Learning
- 지도학습(Supervised Learning) : 정답 세트가 존재하는 데이터를 활용하는 학습 방법
-
판별 분석(Classificaiton Analysis) : 범주형 값을 가지는 종속변수를 예측하는 방법론
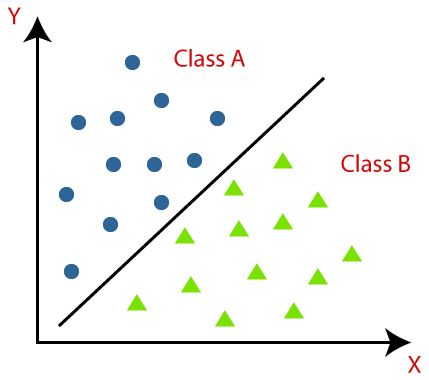
-
회귀 분석(Regression Analysis) : 수치형 값을 가지는 종속변수를 예측하는 방법론
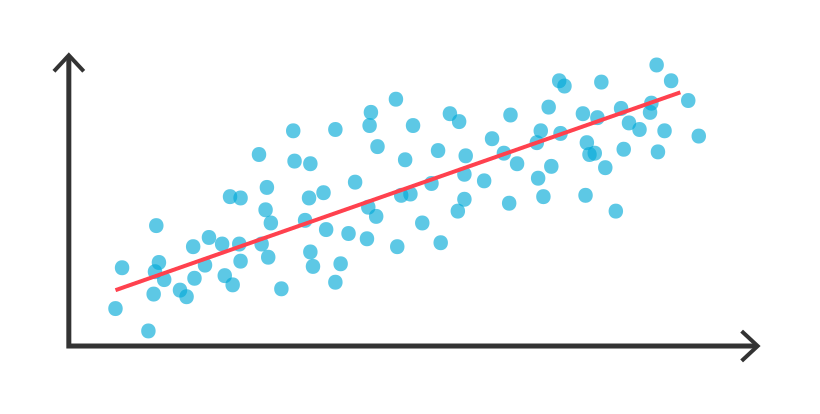
-
- 비지도학습(Unsupervised Learning) : 정답 세트가 존재하지 않는 데이터를 활용하는 학습 방법
-
군집화(Clustering) : 유사한 개체들의 집단을 만든 후 새 개체가 어떤 집단과 유사한지 예측하는 방법론
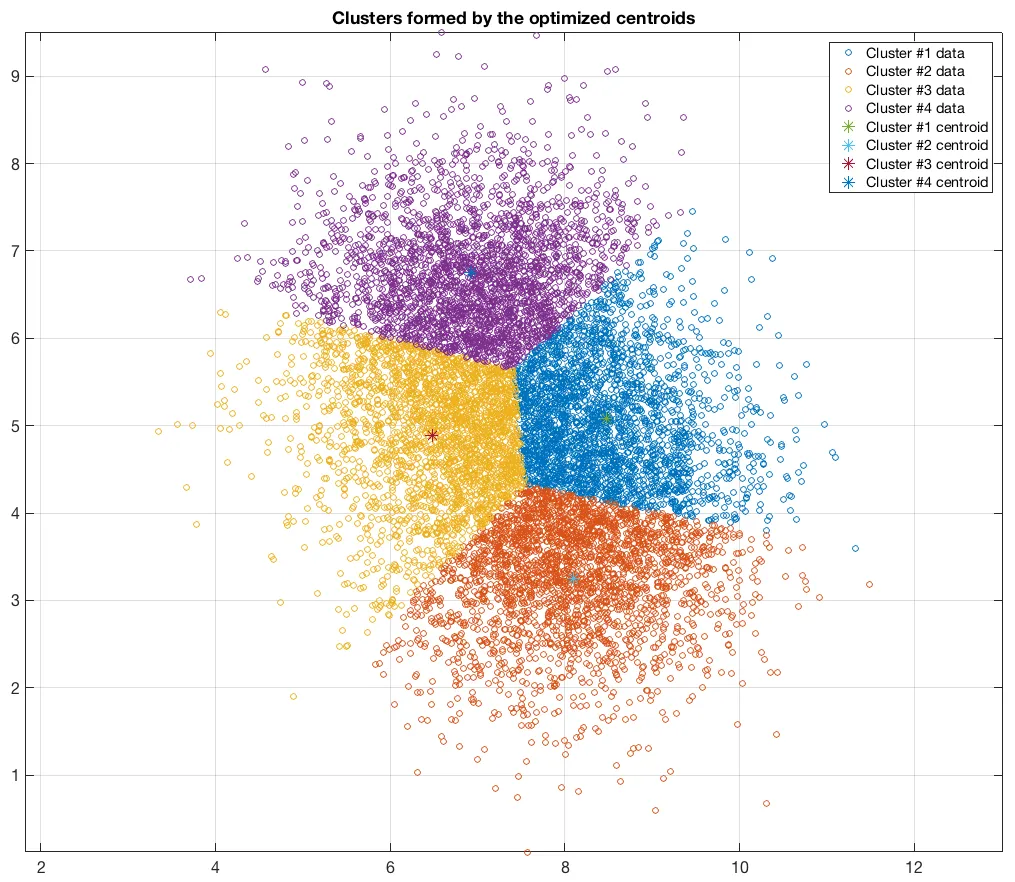
-
차원축소(Dimensionality Reduction) : 고차원 데이터를 저차원 데이터로 변환하는 방법론
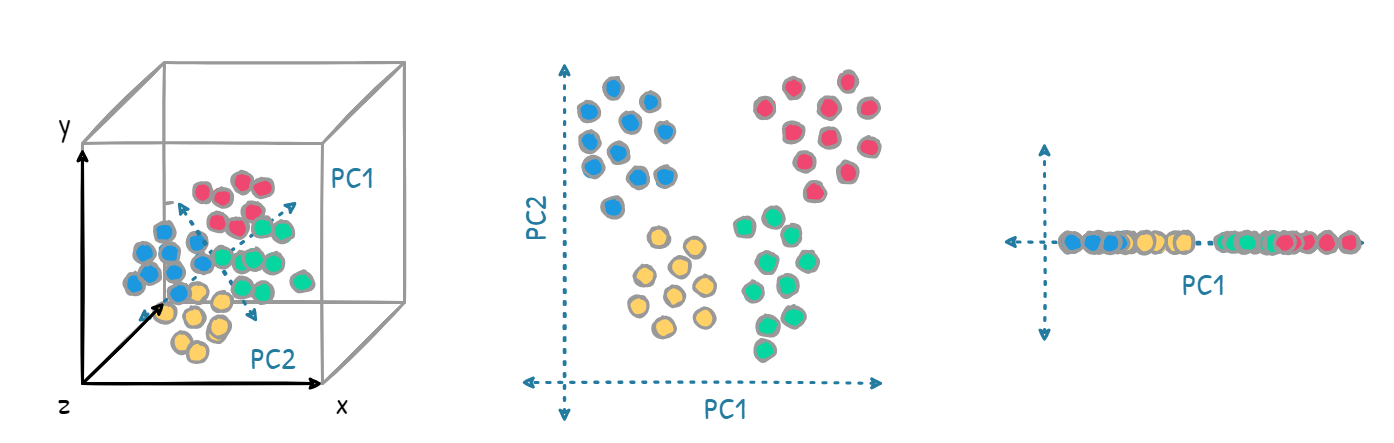
-
Data Preprocessing
-
데이터 전처리(Data Preprocessing) : 데이터를 분석에 사용할 수 있는 형식의 데이터로 만드는 일련의 과정
-
데이터 품질에 영향을 끼치는 인자
- Noise : 데이터 측정 시 무작위로 발생하여 오류를 발생시키는 문제
- Outlier : 대부분의 데이터와 다른 특성을 보이거나 특정 속성의 값이 유별난 데이터
- Artifact : 어떤 요인으로 인해 반복적으로 발생하는 왜곡이나 오류
- Precision : 동일한 결과물을 반복적으로 측정하였을 때 각 측정값 사이의 일관성 문제
- Bias : 측정 장비에 포함된 시스템 상 문제
- Accuacy : 측정 장비의 한계로 정확하지 않은 수를 측정함에 따라 발생하는 문제
- Inconsistent Value : 데이터 불일치 문제
- Duplicate : 데이터 중복 문제
Process
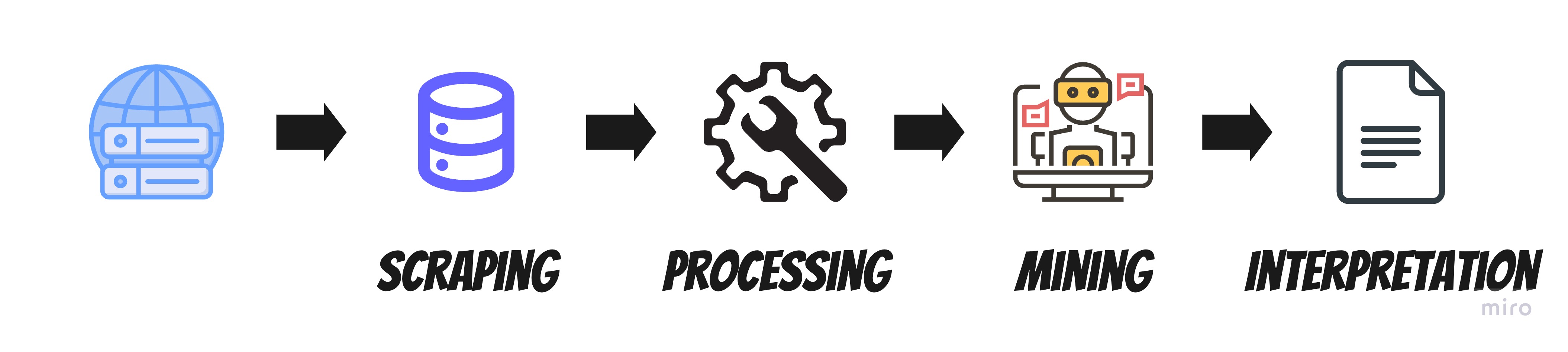
-
Data Integration : 동일한 단위, 양식으로 데이터를 결합하는 절차
- Data Cleansing : 낮은 품질의 데이터를 활용할 수 있도록 하는 절차
- 중복값 제거
- 결측치 처리
- 이상치 처리
- Data Transformation : 데이터 형식 및 구조를 학습에 적합하도록 변환하는 절차
- 표준화(Standardization)
- 정규화(Normalization)
- Data Reduction : 고차원 데이터를 저차원 데이터로 변환하는 절차
Sourse
- https://www.spotfire.com/glossary/what-is-regression-analysis
- https://www.engati.com/glossary/classification-algorithm
- https://medium.com/@baharzerenturk/hierarchical-clustering-analysis-dendogram-6b76f5f33fa8
- https://www.mlguru.ai/Learn/ai-use-cases-dimensionality-reduction