Docs Representation
Based on the lecture “Text Analytics (2024-1)” by Prof. Je Hyuk Lee, Dept. of Data Science, The Grad. School, Kookmin Univ.

Traditional Method
-
BoW(Bag of Words) : 문서를 단어 빈도 수로 표현하는 방법
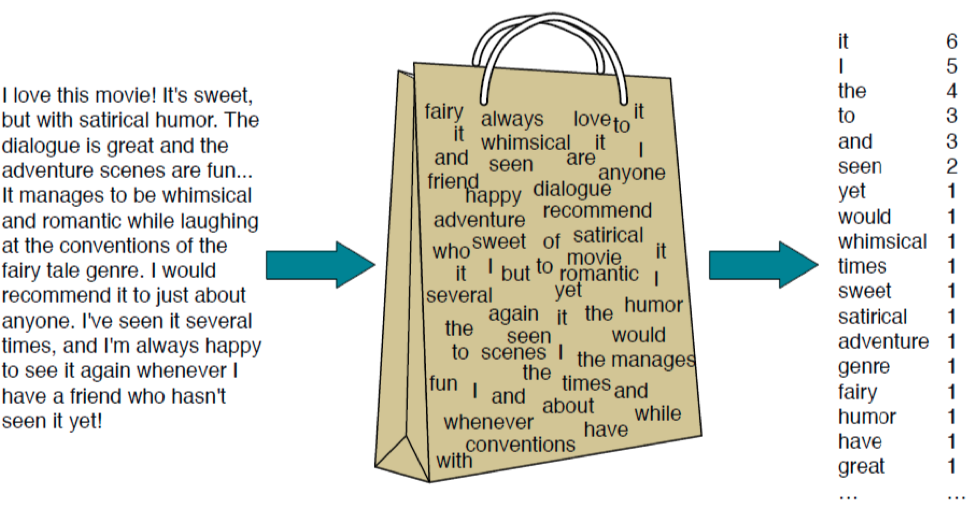
-
DTM(Document Term Matrix) : 여러 개의 문서를 BoW 로 표현하는 방법
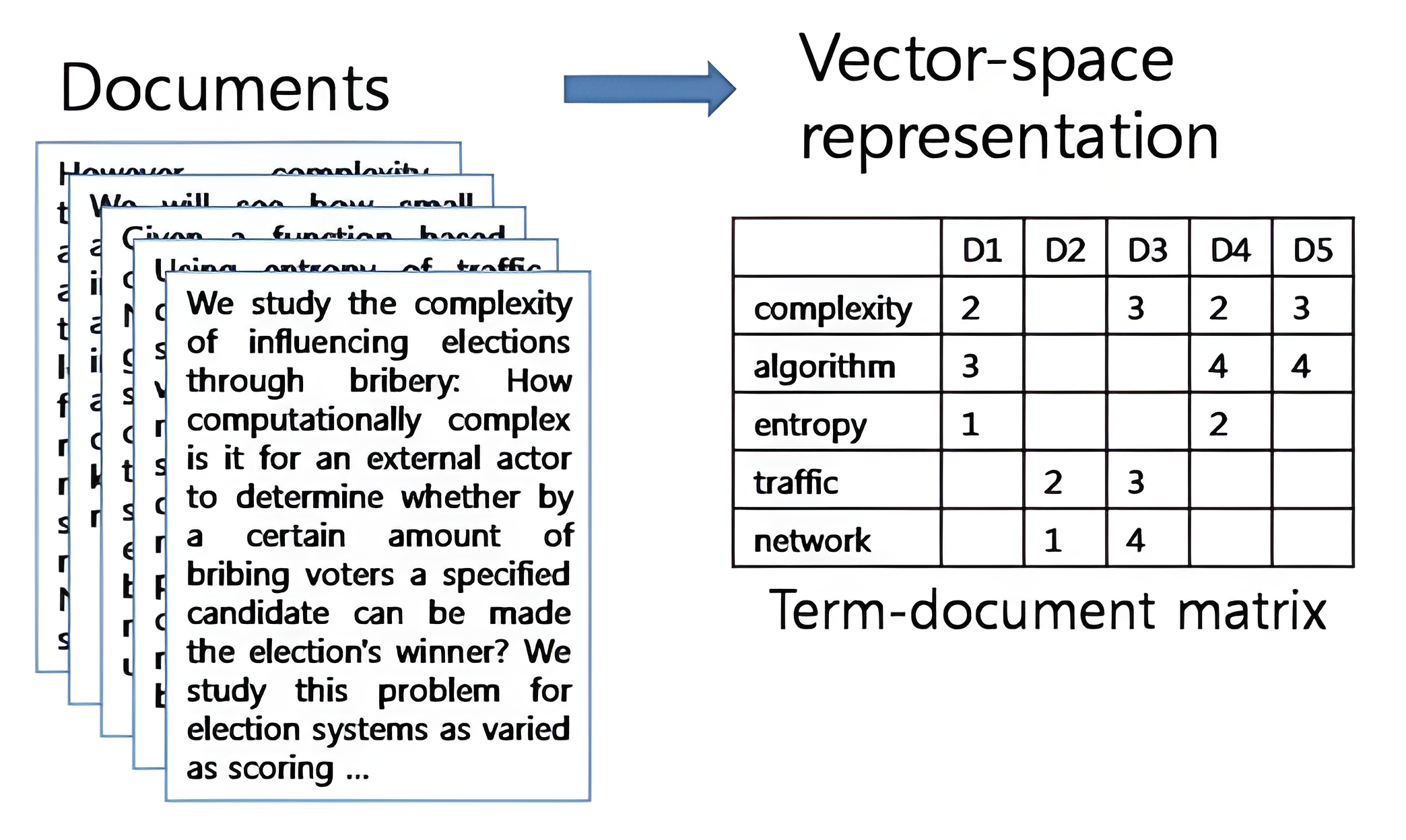
-
TF-IDF(Term Frequency-Inverse Document Frequency) : DTM 내 단어들에 대하여 각 단어의 중요도에 따라 가중치를 부여하여 표현하는 방법
\[\text{TF-IDF}(d,t)=\text{TF}(d,t) \cdot \text{IDF}(t)\]-
TF(Term Frequency) : 문서 $d$ 에서 단어 $t$ 가 등장하는 횟수
\[\text{TF}(d,t)\] -
IDF(Inverse Document Frequency) : 단어 $t$ 가 등장하는 문서의 수에 반비례하는 수
\[\text{IDF}(t)=\ln{\frac{n}{1+\text{DF}(t)}}\]- $n$ : 문서의 수
- $\text{DF}(t)$ : 단어 $t$ 가 등장하는 문서의 수
-
DOC2VEC
-
도큐먼트 투 벡터(DOC2VEC) : WORD2VEC 을 활용하여 문서의 밀집 표현을 학습하는 방법론
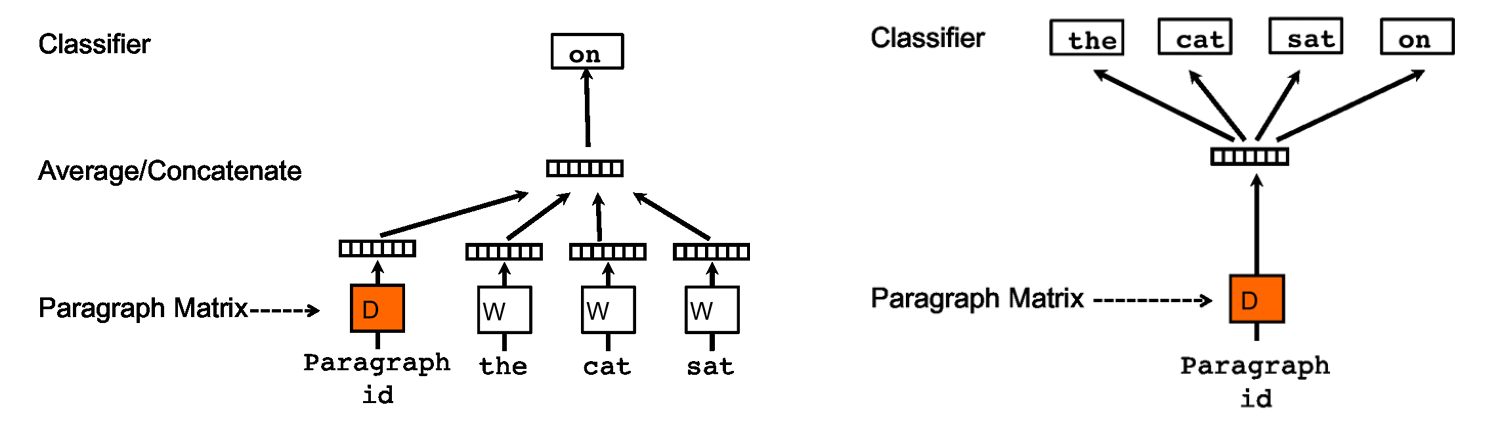
-
PV-DM(
\[\begin{aligned} P\left(w_{t} \mid d, w_{t-\omega}, \cdots, w_{t-1}, w_{t+1}, \cdots, w_{t+\omega}\right) &= \text{Softmax}\left(\mathbf{d} + \sum_{i \in \text{Context}}{\mathbf{w}_{i}}\right) \end{aligned}\]ParagraphVector-DistributedMemory) : WORD2VEC 의 CBOW 와 유사한 학습 방법으로서, 도큐먼트 벡터와 주변 단어 벡터들이 주어졌을 때 발생 가능한 중심 단어 벡터를 추론하는 과정에서 도큐먼트 벡터 표현을 학습함 -
PV-DBOW(
\[\begin{aligned} P\left(\cdots \mid d\right) &= \text{Softmax}\left(\mathbf{d} \cdot \mathbf{W}\right) \end{aligned}\]ParagraphVector-DistributedBagOfWords) : WORD2VEC 의 Skip-Gram 과 유사한 학습 방법으로서, 도큐먼트 벡터가 주어졌을 때 단어들의 발생 확률 분포 벡터를 추론하는 과정에서 도큐먼트 벡터 표현을 학습함