Regular Expression
Based on the lecture “Text Analytics (2024-1)” by Prof. Je Hyuk Lee, Dept. of Data Science, The Grad. School, Kookmin Univ.

Regular Expression
- 정규표현식(Regular Expression) : 특정 문자 패턴을 정의하는 방식
Meta-Character
-
검사 범위 자동 지정
패턴 설명 .개행 문자( \n) 를 제외하고 공백을 포함한 모든 문자\s탭( \t), 개행 문자(\n)\d숫자 \D\d의 검사 범위를 제외한 모든 문자\w알파벳 대소문자와 언더바( _)\W\w의 검사 범위를 제외한 모든 문자 -
검사 범위 수동 지정
패턴 설명 [xyz]x,y,z중 하나[^xyz]x,y,z를 제외한 모든 문자 중 하나(xyz)xyz매칭(?:xyz)xyz매칭x|yzx또는yz -
검사 위치 지정
패턴 설명 ^첫 번째 줄의 시작 $마지막 줄의 끝 \b경계 문자 \B경계 문자 (?=)긍정형 전방 탐색 (?!)부정형 전방 탐색 (?<=)긍정형 후방 탐색 (?<!)부정형 후방 탐색 -
수량 지정
패턴 설명 *$0$ 개 이상 +$1$ 개 이상 ?$0$ 또는 $1$ {n}$n$ 개 {n,}$n$ 개 이상 {,n}$n$ 개 이하 {m,n}$m$ 개 이상 $n$ 개 이하
Python Package re
-
re.compile(pattern)1 2 3 4
import re pattern = ... p = re.compile(pattern, option)
optionNonere.DOTALL: 개행 문자(\n)를 무시하고 매칭함re.IGNORECASE: 대소문자 구분 없이 매칭함re.MULTILINE: 문자열의 각 줄마다 매칭함
-
p.match(my_str): 문자열 처음부터 정규표현식과 매칭되는지 조회함1 2
my_str = ... result = p.match(my_str)
result.group(): 매칭된 문자열을 반환함result.start(): 매칭된 문자열의 시작 위치를 반환함result.end(): 매칭된 문자열의 끝 위치를 반환함result.span(): 매칭된 문자열의 (시작 위치, 끝 위치) 를 튜플로 반환함
-
p.search(my_str): 문자열 전체를 탐색하여 정규표현식과 매칭되는지 조회함1 2
my_str = ... result = p.search(my_str)
-
p.findall(my_str): 정규표현식과 매칭되는 모든 문자열을 반환함1 2
my_str = ... result = p.findall(my_str)
-
p.finditer(my_str): 정규표현식과 매칭되는 모든 문자열을 반복 가능한 객체(iterator)로 반환함1 2
my_str = ... result = p.finditer(my_str)
-
p.sub(re_str, my_str): 정규표현식과 매칭되는 모든 문자열을 다른 문자열로 수정함1 2 3
my_str = ... re_str = ... result = p.sub(re_str, my_str)
Matching Rule of Python
Forward Order
1
2
3
4
5
6
7
8
pattern = '[a-zA-Z0-9]ef[a-zA-Z0-9]'
p = re.complile(pattern)
my_str = "AB12efC1efGH"
results = p.finditer(my_str)
for result in results:
print(result)
-
2efC매칭
-
1efG매칭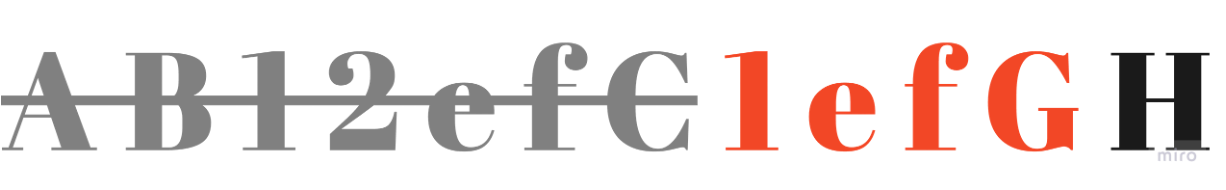
-
추가 매칭되는 문자열 없음
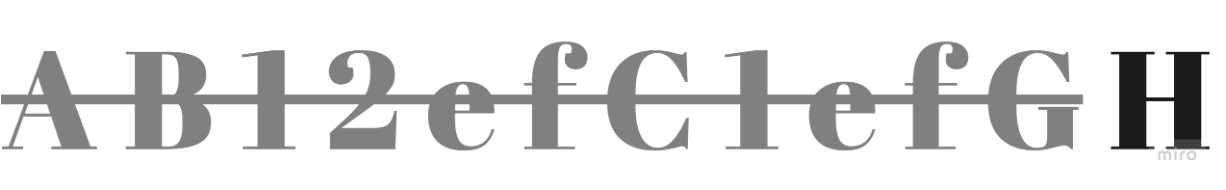
Excluding the Prior Matched
1
2
3
4
5
6
7
8
pattern = '[a-zA-Z0-9]ef[a-zA-Z0-9]'
p = re.complile(pattern)
my_str = "AB12efCefGH"
results = p.finditer(my_str)
for result in results:
print(result)
-
2efC매칭
-
먼저 매칭된 문자열을 제외하고 탐색하므로
CefG는 포함되지 않음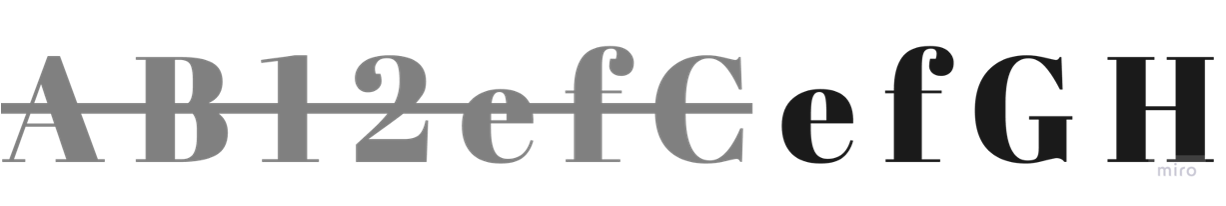
Greedy
1
2
3
4
5
6
7
8
pattern = '[a-zA-Z0-9]+ef[a-zA-Z0-9]'
p = re.complile(pattern)
my_str = "AB12efC1efGH"
results = p.finditer(my_str)
for result in results:
print(result)
-
If Python is not Greedy
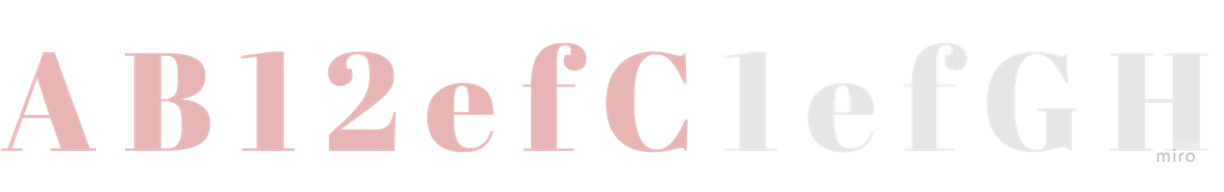
-
But Python is Greedy

Exploration
-
긍정형 전방 탐색
B(?=A): PatternA의 시작점 이전 지점에서 PatternB를 탐색함1 2 3 4 5 6 7 8
pattern = '[a-zA-Z0-9]+(?=efg)' p = re.complile(pattern) my_str = "ABCDefgHIJefgK" results = p.finditer(my_str) for result in results: print(result)

-
긍정형 후방 탐색
(?<=A)B: PatternA의 끝점 이후 지점에서 PatternB를 탐색함1 2 3 4 5 6 7 8
pattern = '(?<=efg)[a-zA-Z0-9]+' p = re.complile(pattern) my_str = "ABCDefgHIJefgK" results = p.finditer(my_str) for result in results: print(result)

-
부정형 전방 탐색
B(?!A): PatternA의 시작점을 제외한 지점에서 PatternB를 탐색함1 2 3 4 5 6 7 8
pattern = '[a-zA-Z0-9]+(?!efg)' p = re.complile(pattern) my_str = "ABCDefgHIJefgK" results = p.finditer(my_str) for result in results: print(result)

-
부정형 후방 탐색
(?<!A)B: PatternA의 끝점을 제외한 지점에서 PatternB를 탐색함1 2 3 4 5 6 7 8
pattern = '(?<!efg)[a-zA-Z0-9]+' p = re.complile(pattern) my_str = "ABCDefgHIJefgK" results = p.finditer(my_str) for result in results: print(result)

Sourse
- https://zephyrus1111.tistory.com/310