SEQ2SEQ
Based on the lecture “Text Analytics (2024-1)” by Prof. Je Hyuk Lee, Dept. of Data Science, The Grad. School, Kookmin Univ.

Machine Translation
-
기계 번역(Machine Translation) : 특정 언어로 표현된 텍스트를 다른 언어로 된 텍스트로 변환하는 과정
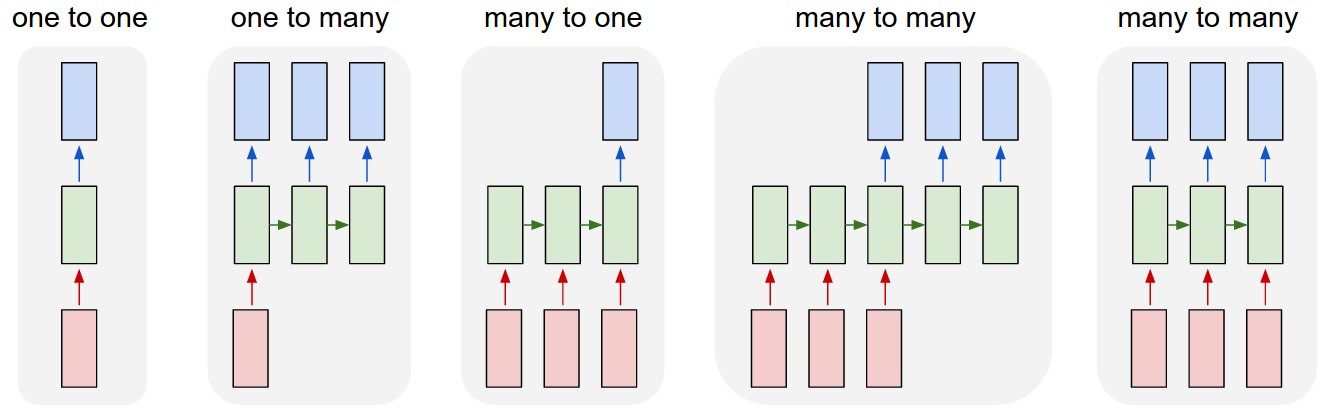
- NLU(
NaturalLanguageUnderstanding) : 특정 언어로 된 텍스트를 이해하는 과정으로서, 해당 텍스트를 벡터 공간에 사상(Projection)하는 절차(Many to One) - NLG(
NaturalLanguageGeneration) : 다른 언어로 된 텍스트를 생성하는 과정으로서, 사상된 벡터를 목표 언어로 변환하는 절차(Many to Many)
- NLU(
-
Brief History
- RBMT(Rule-based Machine Translation) : 규칙 기반 기계 번역
- SMT(Statistical Machine Translation) : 통계적 기계 번역
- NMT(
Neural Networks basedMachineTranslation) : 신경망 기반 기계 번역- Word Embedding
- End-to-End Model
SEQ2SEQ
-
시퀀스 투 시퀀스(SEQ2SEQ) : RNN 계열 레이어 기반 기계 번역 알고리즘
\[\begin{aligned} P(y_{1}, y_{2}, \cdots, y_{T^{\prime}} \mid x_{1}, x_{2}, \cdots, x_{T}) = \prod_{t=1}^{T^{\prime}}{P(y_{t} \mid z, y_{1}, y_{2}, \cdots, y_{t-1})} \end{aligned}\] -
Architecture

-
인코더(Encoder) : 입력 문장의 모든 단어들을 순차로 입력 받아 하나의 문맥 벡터(Context Vector)로 변환하는 모듈(NLU Process)
\[\begin{aligned} h_{t}, c_{t} &= \text{LSTM}\left[\mathbf{x}_{t}, h_{t-1}, c_{t-1}\right] \end{aligned}\]- \(h_{t}\) : $t$ 시점 은닉 상태
- \(c_{t}\) : $t$ 시점 셀 상태
- \(\mathbf{x}_{t}\) : $t$ 번째 단어 임베딩 벡터
- \(\mathbf{z}=h_{T}\) : 마지막 시점 은닉 상태로서 문맥 벡터(Context Vector)
-
디코더(Decoder) : 문맥 벡터를 참조하여 목표 언어의 단어들을 순차로 출력하는 모듈(NLG Process)
\[\begin{aligned} \eta_{t}, \sigma_{t} &= \text{LSTM}\left[\hat{\mathbf{v}}_{t-1}, \eta_{t-1}, \sigma_{t-1}\right] \end{aligned}\]- \(\eta_{t}\) : $t$ 시점 은닉 상태
- \(\eta_{0}=\mathbf{z}\) : 초기 은닉 상태는 문맥 벡터를 할당함
- \(\sigma_{t}\) : $t$ 시점 셀 상태
- \(\hat{\mathbf{y}}_{t}=\text{arg} \max{\text{F}_{\text{Softmax}}\left[\eta_{t}\right]}\) : 목표 언어의 $t$ 시점에서 발생 확률이 가장 높은 단어의 임베딩 벡터
- \(\hat{\mathbf{y}}_{0}\) : 초기 입력값은
<SOS>토큰을 활용함 - \(\hat{\mathbf{y}}_{T}\) : 마지막 출력값은
<EOS>토큰을 활용함
- \(\hat{\mathbf{y}}_{0}\) : 초기 입력값은
- \(\eta_{t}\) : $t$ 시점 은닉 상태
-
-
교사 강요(Teacher Forcing) : 디코더 학습 과정에서, 다음 시점의 입력으로서 이전 시점에서 생성한 출력값 대신 정답 시퀀스를 사용하는 기법
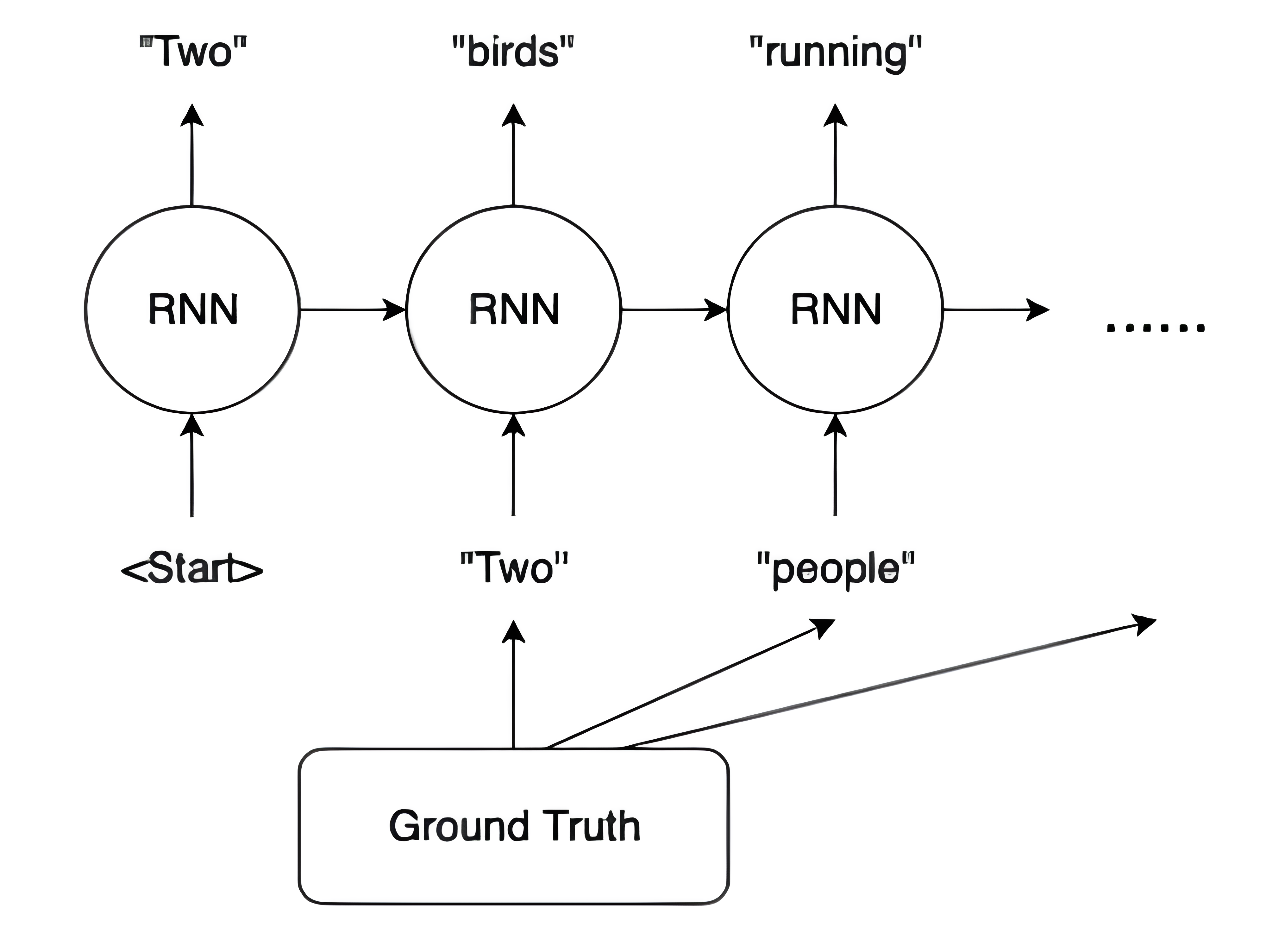
-
Training Phase : 정답 시퀀스 \(\mathbf{y}_{t-1}\) 를 입력값으로 사용함
\[\begin{aligned} \eta_{t}, \sigma_{t} &= \text{LSTM}\left[\mathbf{y}_{t-1}, \eta_{t-1}, \sigma_{t-1}\right] \end{aligned}\] -
Inference Phase : 이전 시점에서 생성한 출력값 \(\hat{\mathbf{y}}_{t-1}\) 를 입력값으로 사용함
\[\begin{aligned} \eta_{t}, \sigma_{t} &= \text{LSTM}\left[\hat{\mathbf{y}}_{t-1}, \eta_{t-1}, \sigma_{t-1}\right] \end{aligned}\]
-
Metric
-
BLEU Score(
\[\begin{aligned} \text{BLEU} &= \text{BP} \cdot \exp{\left[\sum_{n=1}^{N}{w_{n}\cdot\log{P_{n}}}\right]} \end{aligned}\]Bi-LingualEvaluationUnderstudy Score) : 기계 번역 및 자연어 생성에서 기계 번역 결과와 기준 텍스트 간의 유사성을 정량화하는 성능 평가 지표 -
$\text{BP}$ : 길이 패널티(Brevity Penalty)로서, 생성된 문장(Hypothesis)이 참조 문장(Reference)보다 지나치게 짧을 경우 패널티를 부여함
\[\begin{aligned} \text{BP} = \begin{cases} 1 \quad & h > r\\ \exp{\left[1-\displaystyle\frac{r}{h}\right]} \quad & h \le r \end{cases} \end{aligned}\]- $h$ : 생성된 문장(Hypothesis)의 길이
- $r$ : 참조 문장(Reference)의 길이
-
$P_{n}$ : $n-\text{gram}$ 정밀도로서, 생성된 문장(Hypothesis)과 참조 문장(Reference) 간 $n-\text{gram}$ 중복 비율
\[\begin{aligned} P_{n} &= \frac{\sum_{n-\text{gram} \in \text{Hypothesis}}{\min{\Big[\text{Count}_{\text{Hypothesis}}(n-\text{gram}), \text{Count}_{\text{Reference}}(n-\text{gram})\Big]}}}{\sum_{n-\text{gram} \in \text{Hypothesis}}{\text{Count}_{\text{Hypothesis}}(n-\text{gram})}} \end{aligned}\]Why not intersection?
생성된 문장을 기준으로(분모로) 하는 정밀도 특성 상, 참조 문장과의 교집합에 해당하는 특정 유니그램이 반복 생성되었을 때 성능이 과대평가되는 것을 방지하기 위하여 참조 문장에서 등장하는 최대 횟수까지만 매칭을 인정함- \(\text{Count}_{\text{Hypothesis}}(n-\text{gram})\) : 생성된 문장(Hypothesis)의 유니그램 중 특정 $n-\text{gram}$ 등장 횟수
- \(\text{Count}_{\text{Reference}}(n-\text{gram})\) : 참조 문장(Reference)의 유니그램 중 특정 $n-\text{gram}$ 등장 횟수
-
\(\sum_{n=1}^{N}{w_{n}\cdot\log{P_{n}}}\) : $n-\text{gram}$ 정밀도 가중 평균
- 통상 가중치 $w_{n}$ 은 균등하게 분배함
Sourse
- https://yjjo.tistory.com/35