Principal Component Analysis
Based on the lecture “Intro. to Machine Learning (2023-2)” by Prof. Je Hyuk Lee, Dept. of Data Science, The Grad. School, Kookmin Univ.

Principal Component Analysis
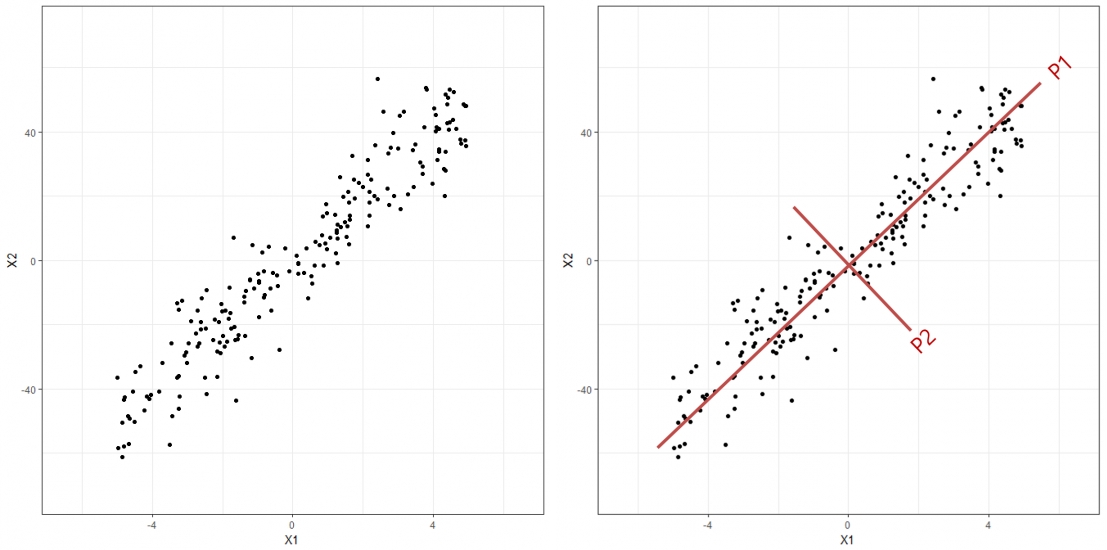
-
주성분 분석(
PrincipalComponentAnalysis): 고차원 데이터 $X$ 의 방향적 분포를 가장 잘 설명하는 새로운 저차원 직교 좌표를 학습하는 기법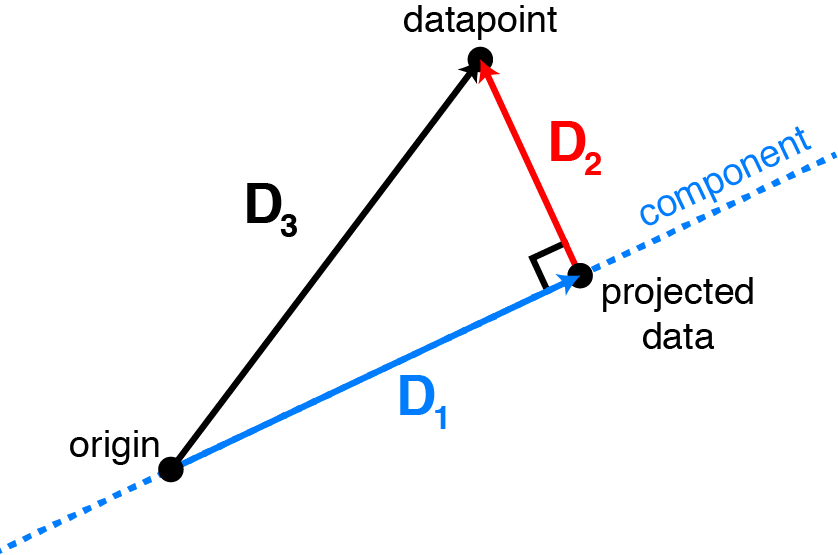
- $\text{component}$ : 주성분 벡터 $\mathbf{w}$
- $\text{datapoint}$ : 관측치 벡터 $\mathbf{x}\in \mathbf{X}$
- $\text{projected data}$ : 주성분 벡터에 대한 관측치 벡터의 정사영 벡터 $\text{proj}_{\mathbf{w}}(\mathbf{x})$
- $D_{1}$ : 관측치 벡터에 대하여 보존하는 정보로서 분산
- $D_{2}$ : 관측치 벡터에 대하여 유실하는 정보
- $D_{3}$ : 관측치 벡터의 본래 정보
How to Extract
-
관측치 행렬 $X_{N \times P}$ 를 단위벡터 $\mathbf{w}$ 에 정사영한다고 하자
\[\begin{aligned} proj_{\mathbf{w}}(\mathbf{X}) &= \frac{<\mathbf{X},\mathbf{w}>}{\Vert w \Vert ^2}\cdot\mathbf{w}\\ &= (\mathbf{w}^{T}\mathbf{X})\cdot\mathbf{w} \quad (\because \Vert w \Vert=1) \end{aligned}\]- $\mathbf{w}$ : 정사영 벡터의 방향
- $\mathbf{w}^{T}\mathbf{X}$ : 정사영 벡터의 크기
-
$\mathbf{w}$ 에 정사영된 관측치들의 분산 $\mathbf{V}$ 은 다음과 같음
\[\begin{aligned} \mathbf{V} &= \frac{1}{n}(\mathbf{w}^{T}\mathbf{X})(\mathbf{w}^{T}\mathbf{X})^{T}\\ &= \frac{1}{n}(\mathbf{w}^{T}\mathbf{X}\mathbf{X}^{T}\mathbf{w})\\ &= \mathbf{w}^{T}\Sigma\mathbf{w} \end{aligned}\]- $\Sigma=\displaystyle\frac{1}{n}\mathbf{X}\mathbf{X}^{T}$ : 관측치 행렬 $X$ 의 공분산 행렬
-
$\mathbf{V}$ 을 최대화하는 $\mathbf{w}$ 를 채택한다고 하자
\[\hat{\mathbf{w}} = \text{arg} \max_{\mathbf{w}}{\mathbf{w}^{T}\Sigma\mathbf{w}} \quad \text{s.t.} \quad \mathbf{w}^{T}\mathbf{w}=1\] -
라그랑주 승수법에 기초하여 $\hat{\mathbf{w}}$ 도출
\[\begin{aligned} L(\mathbf{w},\lambda) &= \mathbf{w}^{T}\Sigma\mathbf{w}-\lambda(\mathbf{w}^{T}\mathbf{w}-1)\\ \frac{\partial L(\mathbf{w},\lambda)}{\mathbf{w}} &= 0\\ \therefore (\Sigma-\lambda\mathbf{I})\hat{\mathbf{w}} &=0 \end{aligned}\] -
$\mathbf{V}$ 를 최대화하는 주성분 $\mathbf{w}$ 은 $\mathbf{X}$ 의 공분산 행렬 $\Sigma$ 의 고유벡터임
\[\begin{aligned} \Sigma &= \mathbb{V}\mathbb{\Lambda}\mathbb{V}^{-1},\\ \mathbb{V} &= \begin{pmatrix}\mathbf{w}_{1}&\mathbf{w}_{2}&\cdots&\mathbf{w}_{p}\end{pmatrix}\\ \mathbb{\Lambda} &= \text{diag}(\lambda_{1},\lambda_{2},\cdots,\lambda_{p}) \end{aligned}\] -
주성분 벡터의 고유값은 관측치 행렬 $\mathbf{X}$ 에 대하여 주성분 벡터에 대한 정사영 벡터 간 분산을 나타냄
\[\begin{aligned} \mathbf{V} &= \frac{1}{n}(\mathbf{w}^{T}\mathbf{X})(\mathbf{w}^{T}\mathbf{X})^{T}\\ &= \frac{1}{n}\mathbf{w}^{T}\mathbf{X}\mathbf{X}^{T}\mathbf{w}\\ &= \mathbf{w}^{T}\Sigma\mathbf{w}\\ &= \hat{\mathbf{w}}^{T}\lambda\hat{\mathbf{w}} \quad (\because \Sigma\hat{\mathbf{w}}-\lambda\hat{\mathbf{w}}=0)\\ &= \lambda \quad (\because \mathbf{w}^{T}\mathbf{w}=1) \end{aligned}\] -
주성분 벡터의 설명력은 관측치 행렬 $\mathbf{X}_{N \times P}$ 에 대하여 생성 가능한 $P$ 개의 주성분 벡터 고유값 합계 대비 해당 주성분 벡터 고유값 비율이 됨
\[\frac{\lambda_{k}}{\sum_{i=1}^{p}{\lambda_{i}}}\]
Linear Discriminant Analysis
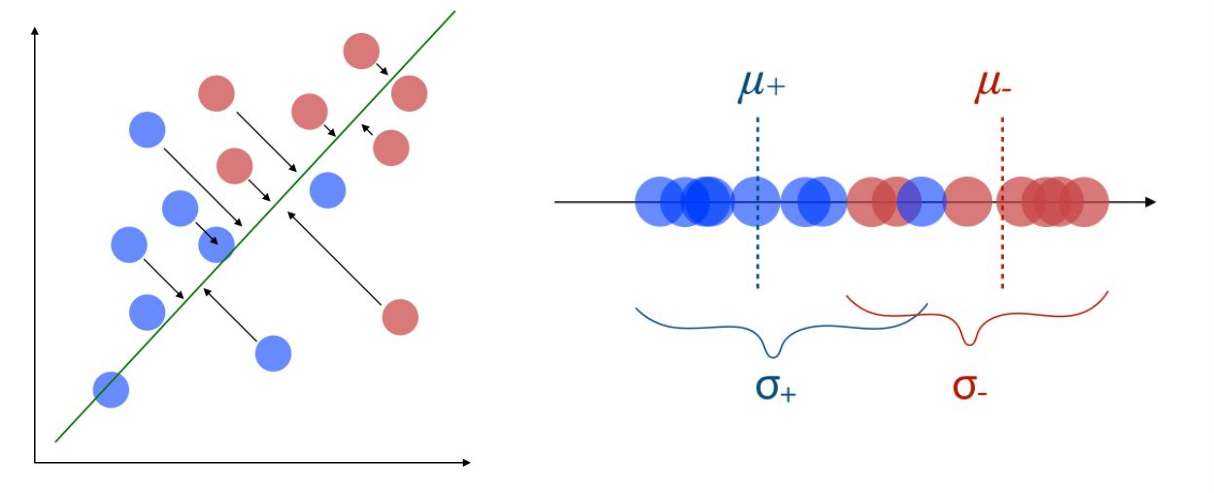
-
선형 판별 분석(
\[\hat{\mathbf{w}} =\text{arg} \max_{\mathbf{w}}{\frac{\Sigma^{2}}{\sigma_{1}^{2}+\sigma_{2}^{2}}} \quad \text{s.t.} \quad \mathbf{w}^{T}\mathbf{w}=1\]LinearDiscriminantAnalysis): 고차원 데이터에 대하여, 주어진 범주를 가장 잘 구분할 수 있는 새로운 저차원 직교 좌표(선형 판별 함수)를 찾는 기법- $\Sigma^{2}$ : 정사영 후 클래스 간 분산
- $\sigma_{i}^{2}$ : 정사영 후 $i$ 번째 클래스 내 관측치 간 분산
How to Extract
-
정사영 후 범주 간 분산 $\Sigma^{2}$:
\[\begin{aligned} \Sigma^{2} &= (\mathbf{\mu}_{1}-\mathbf{\mu}_{2})(\mathbf{\mu}_{1}-\mathbf{\mu}_{2})^{T}\\ &= (\mathbf{w}^{T}\mathbf{m}_{1}-\mathbf{w}^{T}\mathbf{m}_{2})(\mathbf{w}^{T}\mathbf{m}_{1}-\mathbf{w}^{T}\mathbf{m}_{2})^{T}\quad(\because \mathbf{\mu}_{i}=\mathbf{w}^{T}\mathbf{m}_{i})\\ &= \mathbf{w}^{T}(\mathbf{m}_{1}-\mathbf{m}_{2})(\mathbf{m}_{1}-\mathbf{m}_{2})^{T}\mathbf{w}\\ &= \mathbf{w}^{T}\mathbf{S}_{B}\mathbf{w} \end{aligned}\]- \(\mathbf{m}_{i}\) : \(i\) 번째 범주 \(C_{i}\) 의 중심점 벡터
- \(\mathbf{\mu}_{i}=\text{proj}_{\mathbf{w}}(\mathbf{m}_{i})\) : \(\mathbf{m}_{i}\) 의 정사영 벡터
- \(\mathbf{S}_{B}\) : 범주 \(C_{i},C_{j}\) 간 편차
- \(\Sigma\) : 정사영 후 범주 \(C_{i},C_{j}\) 간 편차
-
정사영 후 범주 내 분산 $\sigma_{i}^{2}$:
\[\begin{aligned} \sigma_{i}^{2} &= \sum_{j=1}^{ \vert C_{i} \vert }{(\mathbf{y}_{j}-\mathbf{\mu}_{i})(\mathbf{y}_{j}-\mathbf{\mu}_{i})^{T}}\quad(\mathbf{x}_{j} \in C_{i})\\ &= \sum_{j=1}^{ \vert C_{i} \vert }{(\mathbf{w}^{T}\mathbf{x}_{j}-\mathbf{w}^{T}\mathbf{m}_{i})(\mathbf{w}^{T}\mathbf{x}_{j}-\mathbf{w}^{T}\mathbf{m}_{i})^{T}}\quad(\because \mathbf{y}_{j}=\mathbf{w}^{T}\mathbf{x}_{j})\\ &= \mathbf{w}^{T}\left[\sum_{j=1}^{ \vert C_{i} \vert }{(\mathbf{x}_{j}-\mathbf{m}_{i})(\mathbf{x}_{j}-\mathbf{m}_{i})^{T}}\right]\mathbf{w}\\ &= \mathbf{w}^{T}\mathbf{S}_{i}\mathbf{w} \end{aligned}\]- \(\mathbf{x}_{j} \in C_{i}\) : \(i\) 번째 범주 \(C_{i}\) 의 \(j\) 번째 관측치 벡터
- \(\mathbf{y}_{j}=\text{proj}_{\mathbf{w}}(\mathbf{x}_{j})\) : \(\mathbf{x}_{j}\) 의 정사영 벡터
- \(S_{i}\) : \(i\) 번째 범주 \(C_{i}\) 의 범주 내 관측치 간 편차
- \(\sigma_{i}\) : 정사영 후 \(i\) 번째 범주 \(C_{i}\) 의 범주 내 관측치 간 편차
-
목적 함수 재정의:
\[\begin{aligned} \hat{\mathbf{w}} =\text{arg} \max_{\mathbf{w}}{\frac{\mathbf{w}^{T}\mathbf{S}_{B}\mathbf{w}}{\mathbf{w}^{T}(\mathbf{S}_{1}+\mathbf{S}_{2})\mathbf{w}}} \quad \text{s.t.} \quad \mathbf{w}^{T}\mathbf{w}=1 \end{aligned}\] -
라그랑주 승수법:
\[\begin{aligned} L(\mathbf{w},\lambda) &= \frac{\mathbf{w}^{T}\mathbf{S}_{B}\mathbf{w}}{\mathbf{w}^{T}(\mathbf{S}_{1}+\mathbf{S}_{2})\mathbf{w}}-\lambda(\mathbf{w}^{T}\mathbf{w}-1)\\ \frac{\partial L(\mathbf{w},\lambda)}{\partial \mathbf{w}} &= 0\\ \therefore \left[\mathbf{S}_{B}^{-1}(\mathbf{S}_{1}+\mathbf{S}_{2})-\lambda\mathbf{I}\right]\hat{\mathbf{w}} &=0 \end{aligned}\]
Sourse
- http://alexhwilliams.info/itsneuronalblog/2016/03/27/pca/
- https://maelfabien.github.io/machinelearning/LDA/